编译原理与编译器之路
13 Nov 2020 0前前序
自建立博客开始已经整整过去了28天之久,终于要迎来我的第一篇正式博客了。确实是拖了挺久,但确实是希望能总结出有点质量和有意义的东西,所以还是慢工出细活吧(虽然可能也不是很细)。本科没有修编译原理的坑终于在这里统统还了回来,所以学CS还是得扎实呀。(我挺不扎实的~)
前序
知乎上有一篇文章——《如何看待程序员的三大浪漫被认为是操作系统、编译原理和图形学?》,里面有一句很经典的话,“浪漫自古都是和浪费联系在一起的,花费一大堆时间却不一定有产出的事情就叫做浪漫”,而学习编译原理确实就是这么一门“浪漫”的事情。其实以前在用各种编程IDE的时候都会有简单类似▶️这样的“run”按钮,写好简单的程序后,就会一键完成编译以及运行,在窗口弹出结果。那这期间到底发生了什么?
编译原理—introduction
编译编译,说成白话其实就是“翻译”,但它通常是将一种高级语言翻译为另一种低级语言的过程,而编译器or解释器自然就是实现这一过程的程序。而一个现代编译器的主要流程可以概括为:源代码(source code) →预处理器(preprocessor) → 编译器 (compiler) →目标代码(object code) →链接器(Linker) → 可执行程序(executables)。
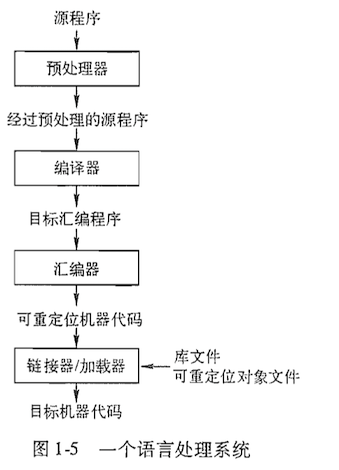
那编译器和解释器的区别是什么呢?
- 编译器:在翻译过程中一步一步完成上述步骤并会汇报期间所遇到的任何错误。其优点就是编译器最终生成的机器码通常完成input到output的过程要更快。如执行效率较高的C++。
- 解释器:通常会比编译器提供更好的错误诊断,因为它是逐句逐句的翻译程序并允许。如灵活性好但是效率有所逊色的python。
而实际上现在有编译和解释融合的趋势,如Jave就是将代码编译成byte code后由JVM来解释执行,实现良好的跨平台可移植性,同时也引入JIT(just in time)来在JVM执行时提高运行效率。
一个编译器所完成的工作可以主要分为以下几个阶段
- 词法分析(lexical analysis)
- 语法分析(syntax analysis/parsing)
- 语义分析(semantic analysis)
- 中间代码生成(IR)
- 代码优化(optimization)
- 目标代码生成(code generation)
- 而符号表(symbols)的管理和错误处理则贯穿编译全过程
通常将中间代码生成之前的阶段称为前端(front end),而之后的阶段称为后端(back end)。前端主要是对输入的整个程序的语义进行正确的把握,并生成一个明确的低级或类机器语言的中间表示,通常的中间表示形式有语法树和三地址代码,该中间表示应该具有两个重要性质:
- 易于生成
- 且能够便于优化与轻松翻译成目标机器上的语言(machine code)。
前面介绍的这些编译器中的多个阶段其实可以被合并为一个pass,比如词法、语法、语义分析和中间代码生成就可以组合成一个pass,也就是前端,而代码优化可以作为一个可选的pass,目标代码生成则可以作为后端pass。有些编译器就是围绕一组精心设计的中间表示形式创建的(如LLVM),使用中间表示形式,我们可以将不同的前端和不同的目标机器后端结合起来,建立起针对不同目标机器的编译器。
如何学习编译原理
这个问题个人认为还是因人而异,你到底是带着怎样的目的需要去学习编译原理?是否需要针对性地对编译器的某个阶段有进一步的把握?开始我也也询问了身边的大佬,大佬直接让读龙书。行,那就去读,花了一个星期陆陆续续把前两章的引论和语法制导的翻译器流程读完了,确实相当于入了个门,但是这本书的门槛确实不低(要不然也不会叫龙书),因为一个优秀的编译器是极其复杂的,里面涉及到的知识更是需要足够的数学功底才能掌握,所以龙书里大量枯燥晦涩的描述与表达式真的会劝退入门新手(或许这就是“浪漫”吧)。后续我也尝试了观看一些网课和课件的学习(推荐CS143),因为节奏太慢和个人目的原因中途也弃了,还是回过头来看龙书,配着课后习题答案一节一节过确实还是收货不少,但是因为还是主要想把精力留在后端的代码优化学习上,所以前端的部分自己觉得可以配合网上的教程直接动手写一个tiny的编译器来进行理论知识的巩固其实就够了(dirty your hand,实践出真知)。
所以说如何学习一门课程\技术\项目,个人认为前期花费一定时间做好调研以及资料的储备都是比较重要的,弄清楚你的动机与需求,再结合实际情况,就能把事情具体化,这样才更容易得到预期的效果。
先来看一个小例子
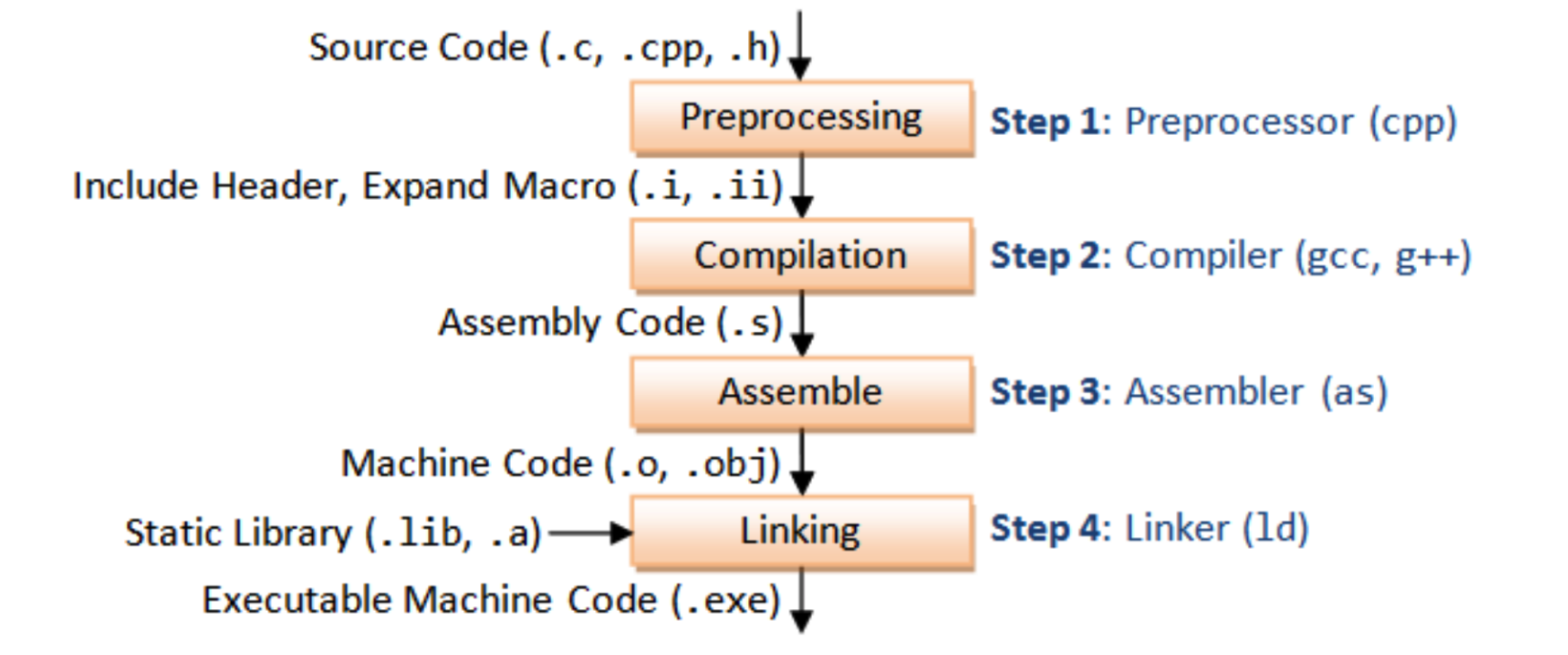
前面介绍了编译一个程序的过程可以简单的分为:预处理、编译、汇编、链接四个阶断,下面我们用最简单的hello world程序来实践一下,用linux的GCC工具来实现一下:
-
Preprocessing:gcc -E -o hello.i hello.c 生成的.i文件就是预处理之后的文件,通常都会在程序头部定义引入的头文件,而预处理器就会读取系统头文件比如stdio.h的内容,并把它直接插入到程序文本中。结果就得到了另一个C程序,通常是以 .i 作为文件扩展名。
-
Compilation: gcc -S -o hello.s hello.i 编译阶段就是将之前的预处理文件编译称为汇编代码,这里的.s输出就是上面介绍的中间表示,掌握汇编语言也是学习编译原理的重要一环,理解汇编才能知道机器如何一步步的执行程序。
-
Assemble: gcc -c -o hello.o hello.s 汇编阶段会将.s文件根据目标机器进一步转成.o的二进制目标文件,打开查看一般为乱码形式。
-
Linking: gcc -o hello hello.o 链接阶段正式将二进制代码打包成一个当前操作系统可以识别的可执行文件格式,linux是elf格式,windows上是pe格式。这里涉及到一个重要概念:函数库(Lib)。hello.c程序中,声明的头文件”stdio.h”中只有该函数的声明,而没有定义函数的实现,那么,是在哪里实现”printf”这些库函数的呢?答案是:系统将这些函数实现都打包名为libc.so.6的动态库文件中去了,在没有特别指定时,gcc会到系统默认的搜索路径”/usr/lib”下进行查找,也就是链接到libc.so.6库函数中去,这样就能实现函数”printf” 了,而这也就是链接的作用。
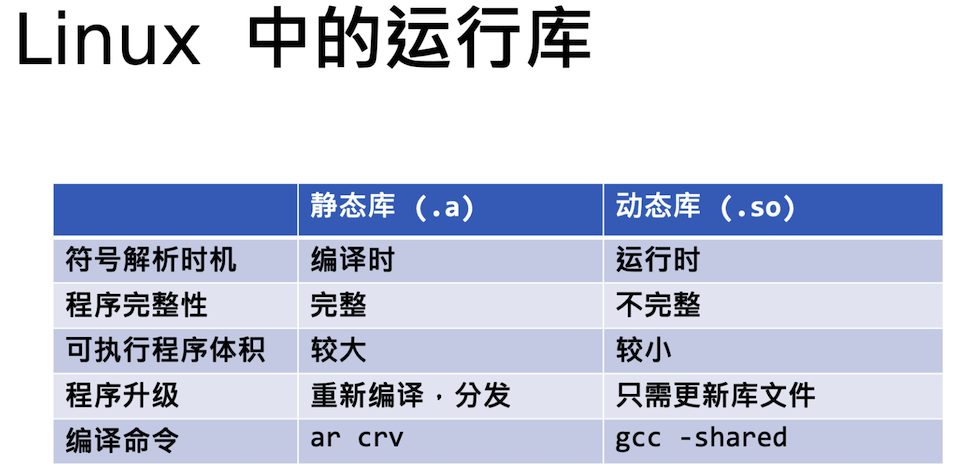
函数库一般分为静态库和动态库两种。静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为”.a”。动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为”.so”,如前面所述的libc.so.6就是动态库。gcc在编译时默认使用动态库。
完成链接后,此时即可运行可执行文件hello,查看输出了。
动手实现一个Tiny Compiler
是不是学了编译原理就能手撸一个编译器了呢?答案必然是不能。那我怎么写的呢?当然是看教程了。一款真正实际应用的编译器开发是无敌复杂的(GCC\LLVM),所以我这里也只是实现一个能读懂程序的程序而已(前端),因为正常的编译原理课程一般也是讲完语义分析就结束了,并且在真正实现一个简单编译器的时候,大部分龙书上的复杂理论是用不上的,而且就算掌握了理论应该依然写不出编译器(浪漫)。
当然在动手写一个简单编译器也得做好心理准备,原因是coding过程十分繁琐,充斥着大量重复工作并且十分不易调试,一方面是没有全面的测试用例,另一方面是需要对照生成的代码来调试。
这里参考的教程当然是出名的C in four function,因为它体量很小就实现了编译器的大部分功能,并且能够实现自举,即编译自身程序。那么C4到底实现了C语言的哪些功能?或者说,哪些C89/C99的功能是它不支持的?

…………….