并行编程-OpenMP
0开放多处理过程(Open Multi-Processing, OpenMP)属于共享内存的并行编程模型。
- 并行应用编译指令/库过程(routine)的集合
- 大大简化写多线程的难度(C/C++/Fortran)
- 标准化过去20年SMP的实践
Fork-join
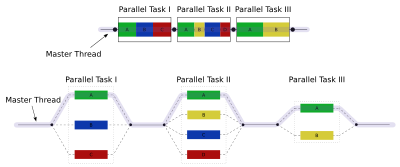 注意这里fork的东西是任务(task)或纤程(fiber/lightweight thread),而不是线程
注意这里fork的东西是任务(task)或纤程(fiber/lightweight thread),而不是线程
基本环境变量
OpenMP提供了三种API
- 编译指示(directive):
#pragma omp <directive-name> [clause,...] - 运行时库例程(routine)
- 环境变量
常用API
omp_get_thread_num():线程idomp_get/set_num_procs:使用的物理核数目omp_get/set_num_threads:使用的线程数目- 没有指明时默认使用
OMP_NUM_THREADS作为环境变量
- 没有指明时默认使用
并行区域
#pragma omp parallel for:循环内不能含跳转、跳出指令,且循环次数应确定- 如果仅仅是
parallel(SPMD编程模型),则循环只是被简单拷贝,循环体执行多次 - 如果是
parallel for,则会触发调度器,内层循环不会被拷贝 - 对于每一个实例都会产生一个fork/join,希望能够最大化一次的执行量(尽可能对较外层循环做并行)
- OpenMP默认关闭嵌套,需要用
omp_set_nested(1)打开
- 如果仅仅是
#pragma omp ... private (<variable list>):将变量声明为私有变量- 每个线程都有这个私有变量的拷贝
- 不可使用先前全局定义的值,也不能再给全局该值赋值
- 私有变量在循环开始前未定义(减少执行时间),可通过
firstprivate(<var>)继承之前定义的值var是基本数据类型:直接拷贝var是数组:拷贝sizeof(var)大小到私有内存空间var是指针:指向同个共享varvar是一个类:调用拷贝构造函数构造私有副本
lastprivate(<var>)返回最后的值至全局
single:单线程执行,如处理IO- 其他线程在代码块结尾等待,除非声明了
nowait
- 其他线程在代码块结尾等待,除非声明了
master:仅对主线程进行操作
tid = omp_get_thread_num();
if (tid == 0) {
nthreads = omp_get_num_threads();
printf("Number of threads = %d\n", nthreads);
}
// 等价于
#pragma omp master
// 近似等价于,在嵌套并行时会有区别
#pragma omp single nowait
语法限制
- 不能使用
!=作为循环终止判断条件- 不可
for(int i = 0; i != 8; ++i)
- 不可
- 循环必须单入口单出口
- 不能使用break、goto等跳转语句
临界区
sections和section:sections作用域内所有的section都可以并行执行- 不同
section可以被不同线程执行,一个线程可以执行多个section
reduction (op:list)- 每一个list中变量依据op被创建且初始化
- 所有的拷贝都被线程局部更新
- 最后所有局部拷贝的值经过op操作归并为一个共享的值
+,-,*,&,|,&&,||
// Example 1
int i, j, k;
float **a, **b;
// initialize b[][] as 1-hop distance matrix
for (k = 0; k < N; ++k)
#pragma omp parallel for private(j)\
num_threads(8)
for (i = 0; i < N; ++i)
for (j = 0; j < M; ++j)
a[i][j] = min(a[i][j], b[i][k] + b[k][j]);
// copy a[][] to b[][]
// Example 2
#pragma omp parallel shared(a,b,c,d) private(i)
{
#pragma omp sections
{
#pragma omp section
{
for (i = 0; i < N; ++i)
c[i] = a[i] + b[i];
}
#pragma omp section
{
for (i = 0; i < N; ++i)
d[i] = a[i] * b[i];
}
} /* end of sections */
}/* end of parallel section */
// Example 3
float sum(const float *a, size_t n)
{
float total = 0.;
#pragma omp parallel for reduction(+:total)
for (size_t i = 0; i < n; i++) {
total += a[i];
}
return total;
}
竞态与同步
数据依赖性
- 循环迭代相关(loop-carried dependence):
a[i] = b[i+1] - 非循环迭代相关(loop-independent dependence):
a[i] = b[i]
竞态(RC)问题出现的原因:多个线程访问同一共享变量的不确定性
避免RC问题的方法:
- 变量作用域限制在线程内:用
private语句,在线程函数内声明变量,分配线程栈 - 用临界区控制共享访问:互斥和同步
下面这种机制由于判断flag和flag置位是两个操作,故并不能保证互斥,需要有原子性的TS(test-and-set)操作,或者锁
// initialize flag = 0
while(flag != 0) /* wait */;
flag = 1;
barrier:同步,类似于join,会被自动添加在worksharing结构中,如for和single;可以通过nowait取消critical:临界区,保证互斥(只有一个线程可以进入),都会变成串行执行atomic:没有冲突的部分会被并行执行,只对单一简单二元语句有用
#pragma omp parallel for
{
for (i = 0; i < n; ++i){
#pragma omp critical
// #pragma omp atomic
x[index[i]] += WorkOne(i);
y[i] += WorkTwo(i);
}
}
// critial保护:WorkOne的调用、index[i]的寻找、自加、赋值
// atomic保护:加法和赋值
循环调度
schedule(static[,chunk]):相当于按照chunk大小循环展开,round-robin,低开销,但会导致负载不均schedule(dynamic[,chunk]):也是按chunk大小循环展开,高开销,但能负载均衡(work-stealing的感觉)schedule(guided[,chunk]):指导性的启发式自调度方法。开始时每个线程会分配到较大的迭代块,之后分配到的迭代块会逐渐递减。迭代块的大小会按指数级下降到指定的chunk大小,如果没有指定chunk参数,那么迭代块大小最小会降到1。
优化方法
衡量指标
- 加速比:\(R=T_{seq}/T_{par}\),核数增加加速比会趋于平缓
- 效率:\(R/N\),核数增加效率会降低
- 改进的Amdahl公式:\(\psi(n,p)\leq\frac{\sigma(n)+\varphi(n)}{\sigma(n)+\varphi(n)/p+\kappa(n,p)}\)
局部性
多核意味着有多个cache,就会有cache一致性问题:一个核cache的写会导致另一个核cache的失效
经验原则(rule of thumb):
- 注意要先将串行程序调到最优才将其并行化
- 不同的核操纵完全不同的数组chunk
一个多核程序具有好的局部性是指一个核的内存写不会与其他核的进行交互。 比如说123123123就不是好的分配方式,而111222333就是较好的局部性。
循环变换
- 裂变(fission):单一循环有跨循环依赖,将循环划分为多个,新的循环能够并行执行
- 融合(fusion):合并循环以增加粒度
- 交换(exchange):展现可并行循环,增加粒度,提升局部性
优点和缺点
- 增量式并行,串行等价
- 对数据划分友好,对任务划分并不友好
- 编译器无法查死锁或RC问题,因是编译指令
编译运行
#include <omp.h>g++ -O3 -fopenmp <source>
实际上OpenMP的编译器就是将OpenMP的语法转为pthreads